
yolov8使用流程的简单教程
下载后将后缀名改成zip 然后解压
脚本文件.txt (3.9 KB)
请使用显示大纲功能查看章节

yolov8官方文档地址:
Home - Ultralytics YOLOv8 Docs
0. 准备
开始之前需要先准备以下事项
0.1 python和opencv的基本使用
yolo目标检测常用的代码环境为python,并且经常需要和opencv配合使用。
推荐教程:
python:
opencv:
独家 | 手把手教你使用OpenCV库(附实例、Python代码解析) - 知乎 (zhihu.com)
0.2 环境的基础配置
需要提前安装pytorch cuda opencv yolov8环境
pytorch安装:
Pytorch安装及配置环境_pytorch环境搭建-CSDN博客
cuda安装:
CUDA安装教程(超详细)-CSDN博客
opencv安装:
python下opencv安装_python安装opencv-CSDN博客
yolov8安装:
pip install ultralytics
0.3 其他平台账号准备(可选)
0.3.1 数据标注平台 百度EasyDL(免费,百度账号登录)
用于标注采集到的图片,百度的这个平台有智能标注的功能,可以减少标注工作量。
EasyDL零门槛AI开发平台 - 百度智能云控制台 (baidu.com)
0.3.2 云GPU平台 Featurize(付费)
此为云GPU平台用于训练模型,平台已经配置好了大多数环境使用起来很方便,并且相对于我们自己的笔记本电脑,性能也是非常强大的。价格也不算太贵。
0.3.3 训练中监测 wandb (免费)
Home – Weights & Biases (wandb.ai)
用于检测训练过程中模型各项参数如:map,loss
0.4 一些概念的了解
0.4.1 loss
损失(Loss)是一个用于衡量模型预测与实际目标之间差异的指标。损失越小,表示模型的预测越接近实际目标,反之则表示模型的预测存在较大的误差。
对于目标检测问题,损失函数的设计旨在衡量模型对边界框位置、尺寸和类别的预测精度。在YOLO等目标检测算法中,总体的损失由多个部分组成,包括框损失(box loss)、类别损失(class loss)等。
0.4.1.1 dfl_loss(Detection Focal Loss)
dfl_loss 是一种在YOLO目标检测中引入的特殊损失函数,它是基于焦点损失(Focal Loss)的改进。焦点损失的主要目标是应对样本不平衡问题,即正负样本比例严重失衡。在目标检测中,负样本(即不含目标的区域)远远多于正样本(含有目标的区域)。dfl_loss 试图通过放大难以分类的正样本的损失,来应对这种不平衡,从而使模型更关注难以识别的目标。
0.4.1.2 box_loss(Box Regression Loss)
这是用于衡量预测框位置的损失函数。在目标检测中,模型不仅要预测目标的类别,还要预测框的位置,即边界框的中心坐标、宽度和高度。box_loss 的目标是使模型的位置预测更接近真实目标框的位置。这有助于确保检测到的框与真实目标框的位置相匹配,从而提高目标定位的准确性。
0.4.1.3 cls_loss(Class Classification Loss)
cls_loss 用于分类目标的类别。在YOLO中,每个检测框需要预测它所属的目标类别。cls_loss 的作用是确保模型的类别预测尽可能准确。这对于准确地将检测框与正确的目标类别关联非常重要,从而实现了目标分类的准确性。
0.4.2 IoU
IoU(Intersection over Union),IoU的计算方式是将预测的目标区域(通常是矩形框或分割区域)与实际目标区域的交集面积除以它们的并集面积。
IoU 的计算公式为:
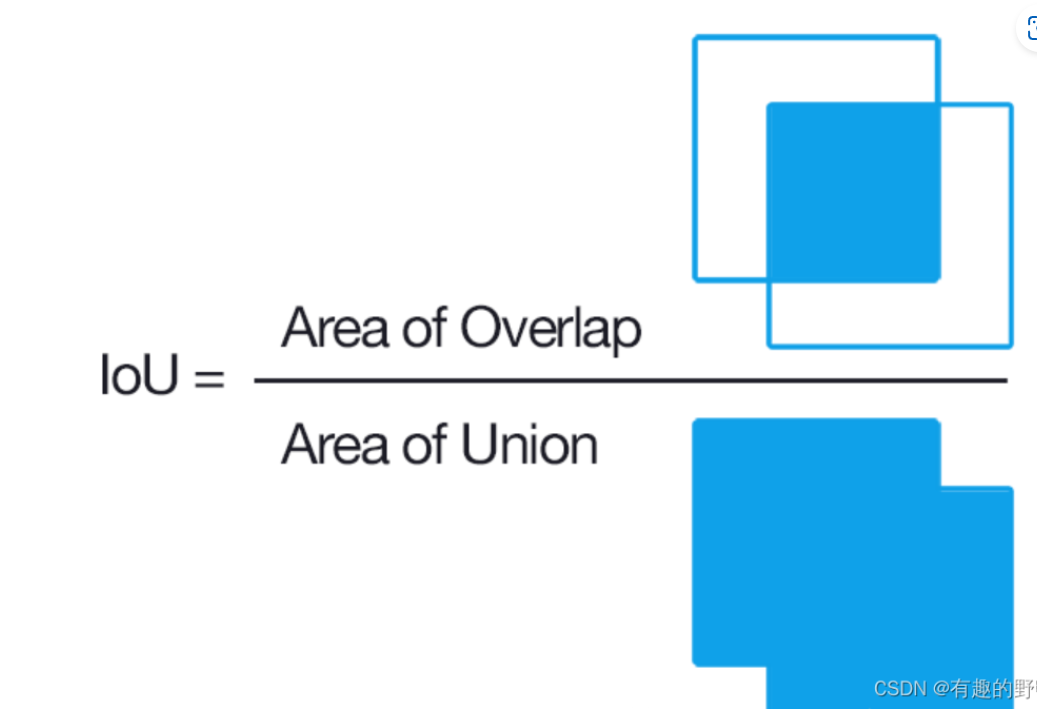
其中:
- Intersection Area 是两个边界框相交的区域面积。
- Union Area 是两个边界框并集的区域面积。
IoU 的值范围在 0 到 1 之间,其中 0 表示没有重叠,1 表示完全重叠。在目标检测任务中,IoU 常常用于衡量模型预测边界框与真实边界框之间的重叠程度。
在评估目标检测算法时,通常会使用 IoU 阈值,例如 0.5,来确定一个检测是否被认为是正确的。如果模型预测的边界框与真实边界框的 IoU 大于等于指
定的阈值,则该检测被视为正确。这种阈值常用于计算 mAP(mean Average Precision)等性能指标。
0.4.3 Precision和Recall
详细解释:
Precision(准确率)和Recall(召回率)介绍_precision recall-CSDN博客
在目标检测中,Precision(精度)和Recall(召回率)是两个常用的性能指标:
- Precision(精度):模型在预测中有多少是正确的,相对于所有预测中的正确和错误。它是衡量模型预测准确性的指标之一。即

- Recall(召回率):模型正确预测的目标数与实际目标数之比。它表示模型能够检测到多少实际目标。召回率是衡量模型识别能力的指标之一。即

在目标检测中,Precision和Recall通常是一对相互牵制的指标,提高一个可能会降低另一个。Precision-Recall曲线绘制了在不同置信度阈值下的Precision和Recall的变化情况。
0.4.4 mAP
mAP(mean Average Precision)是一种用于评估目标检测算法性能的指标。它是Precision-Recall曲线下的平均精度。
mAP是对Precision-Recall曲线的一个综合度量,它计算了不同类别的平均精度,然后再对所有类别的平均精度取平均值。mAP的计算过程通常涉及在不同置信度阈值下计算Precision-Recall曲线下的面积(Area Under the Curve,AUC),然后取平均值。
mAP提供了一个更全面的性能评估,尤其适用于多类别目标检测任务。更高的mAP值通常表示模型在检测任务中具有更好的性能。
mAP50 表示在 IoU 阈值为 0.5 的情况下计算的 mAP。这意味着只有当检测到的边界框与真实边界框的 IoU 大于等于 0.5 时,才被认为是正确的检测。
0.4.5 Ir (learning rate)
学习率是深度学习中的一个重要超参数,用于控制模型参数在训练过程中的更新步长。学习率越大,参数更新的步长越大;学习率越小,步长越小。
在深度学习模型的训练中,优化算法通过计算损失函数关于模型参数的梯度,然后使用学习率来更新这些参数。学习率的选择对模型的训练性能和速度都有重要影响。
一般来说,学习率的选择需要在训练开始时进行调整,并可能需要随着训练的进行进行调整。通常的做法是从一个较小的学习率开始,然后根据模型的性能逐渐调整学习率。如果学习率过大,可能导致模型无法收敛,甚至发散;如果学习率过小,训练可能收敛得很慢。
一些常见的学习率调整策略包括:
- 固定学习率: 在整个训练过程中保持不变的学习率。
- 学习率衰减(Learning Rate Decay): 在训练的特定时刻或特定条件下,逐渐减小学习率,以帮助模型更好地收敛。
- 自适应学习率方法: 例如,Adam、Adagrad、RMSProp等优化算法会根据每个参数的历史梯度自动调整学习率。
学习率的合适选择对于深度学习模型的成功训练至关重要。过大或过小的学习率都可能导致不稳定的训练过程。
1. 数据集
1.1 准备图片
准备图片的要求是:
- 大规模:数据集应该包含大量的图像或视频样本,以便训练和评估算法的性能。这样可以提高模型的泛化能力,并减少过拟合的可能性。
- 多样性:数据集应该包含各种不同的场景、光照条件和目标类别。这样可以使得算法具备更好的适应性和鲁棒性。
- 均衡性:数据集中的目标类别应该具备一定的数量均衡,避免某些类别过于少见导致算法对其的识别性能较差。
1.1.1 手动拍摄数据集
使用摄像头拍摄大量符合要求的图片,摄像头型号最好与部署平台相同,图片要求见上文,拍摄好图片后保存在一个文件夹下。
1.1.2 自动产生数据集
此段为CQUPT HXC独家,保密。
1.1.3 下载数据集
可以从GitHub,Featurize等平台尝试寻找标注好的数据集,也可从百度上寻找图片下载。
1.2 标注数据集
此处采用百度的EasyDL平台
https://console.bce.baidu.com/easydl/objdct/overview
如需本地标注推荐lebalme软件,教程见:深度学习标注软件Labelme的使用 - 知乎 (zhihu.com)
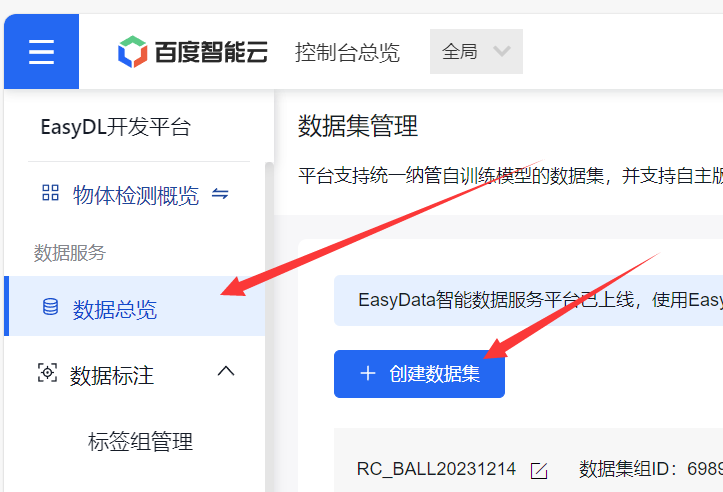
1.2.1 导入数据集
- 点击数据总览-创建数据集
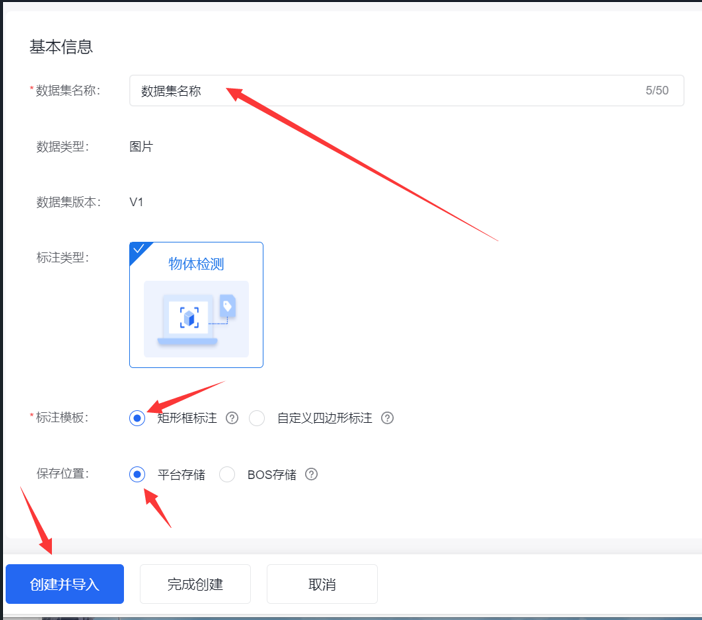
- 填写名称后导入
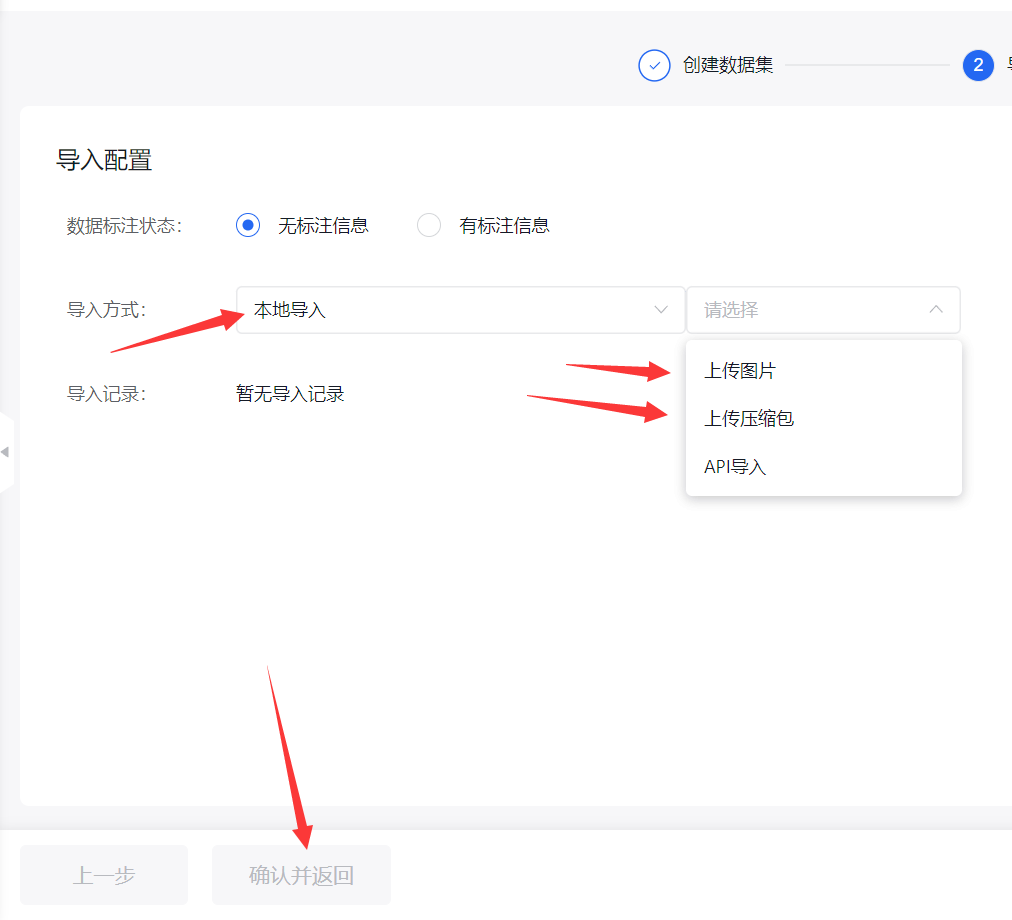
建议将图片打包为压缩包后,通过压缩包(zip或者gz格式)导入
- 等待导入完成

1.2.2 数据清洗(可选)
数据清洗可以对数据集中的图片进行去模糊、去近似,减少标注的工作量的同时不影响AI性能

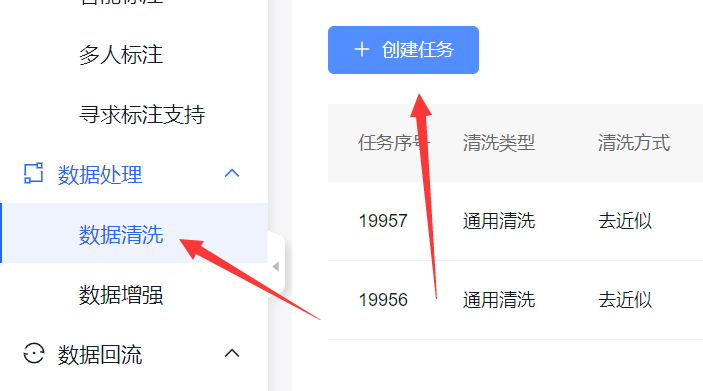
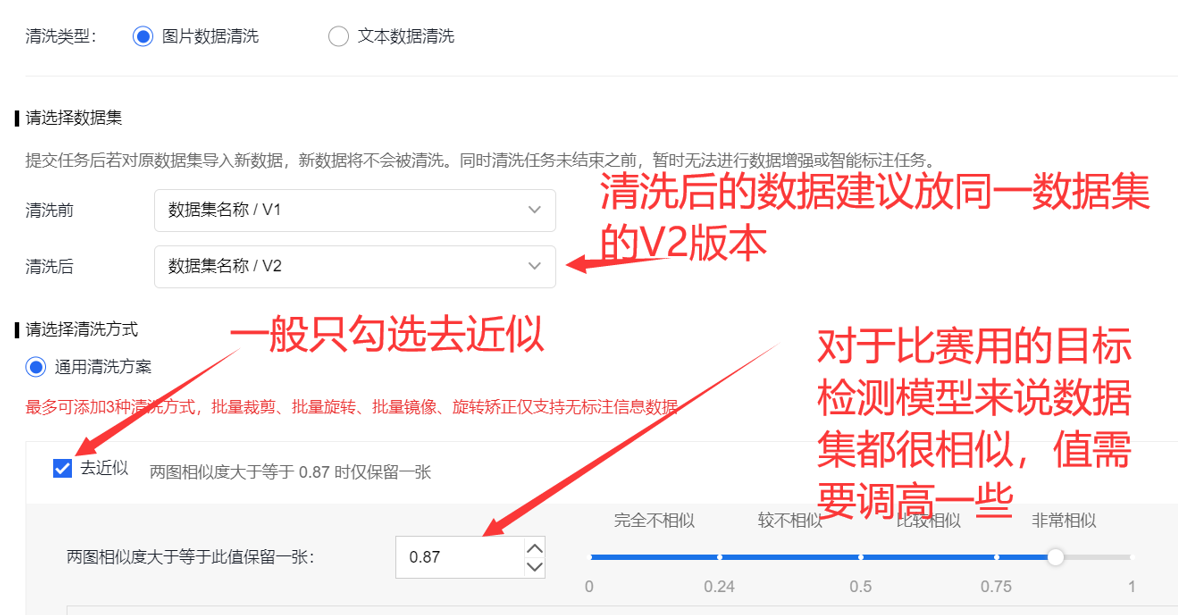
注意之后的所有操作都需要在清洗后的数据集上进行
1.2.3 数据标注
点击在线标注
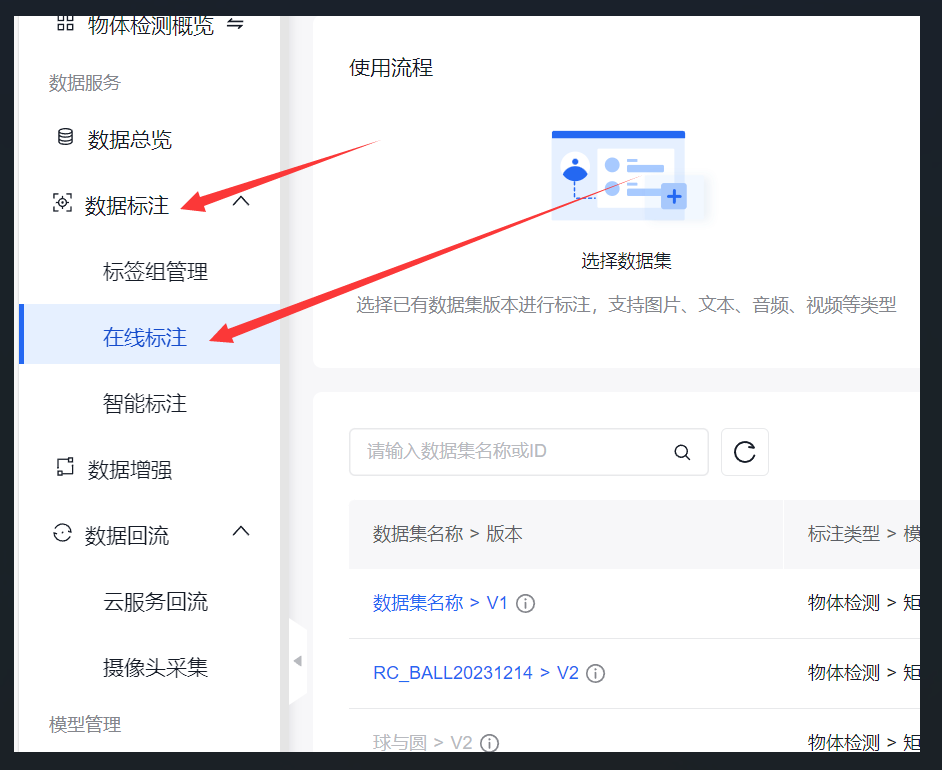
选择要标注的数据集,点击标注
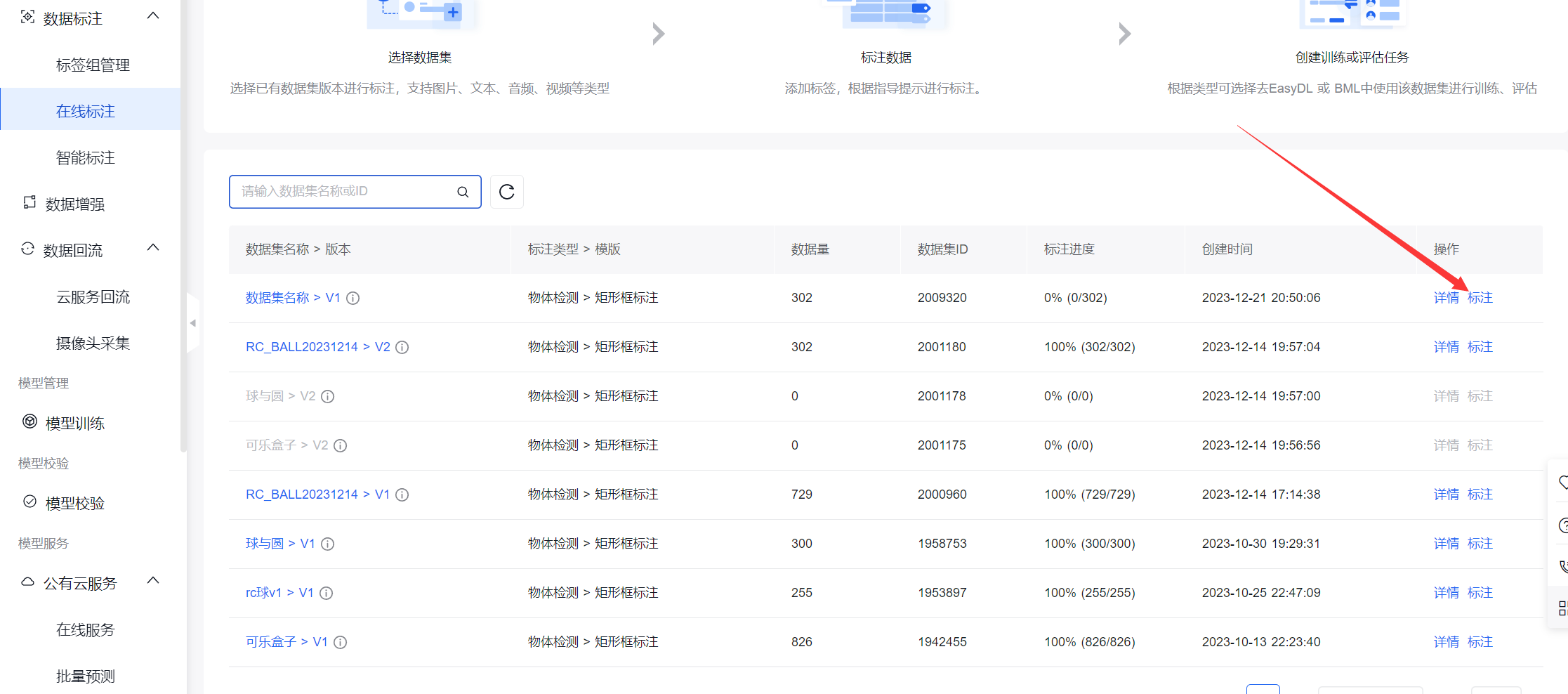
开始标注时,应该添加好该数据集所有需要标注的标签
鼠标左键点击即可画标注框。
画好一个框后用键盘的数字键指定标签。
标好一张图片后使用A/D键切换图片。
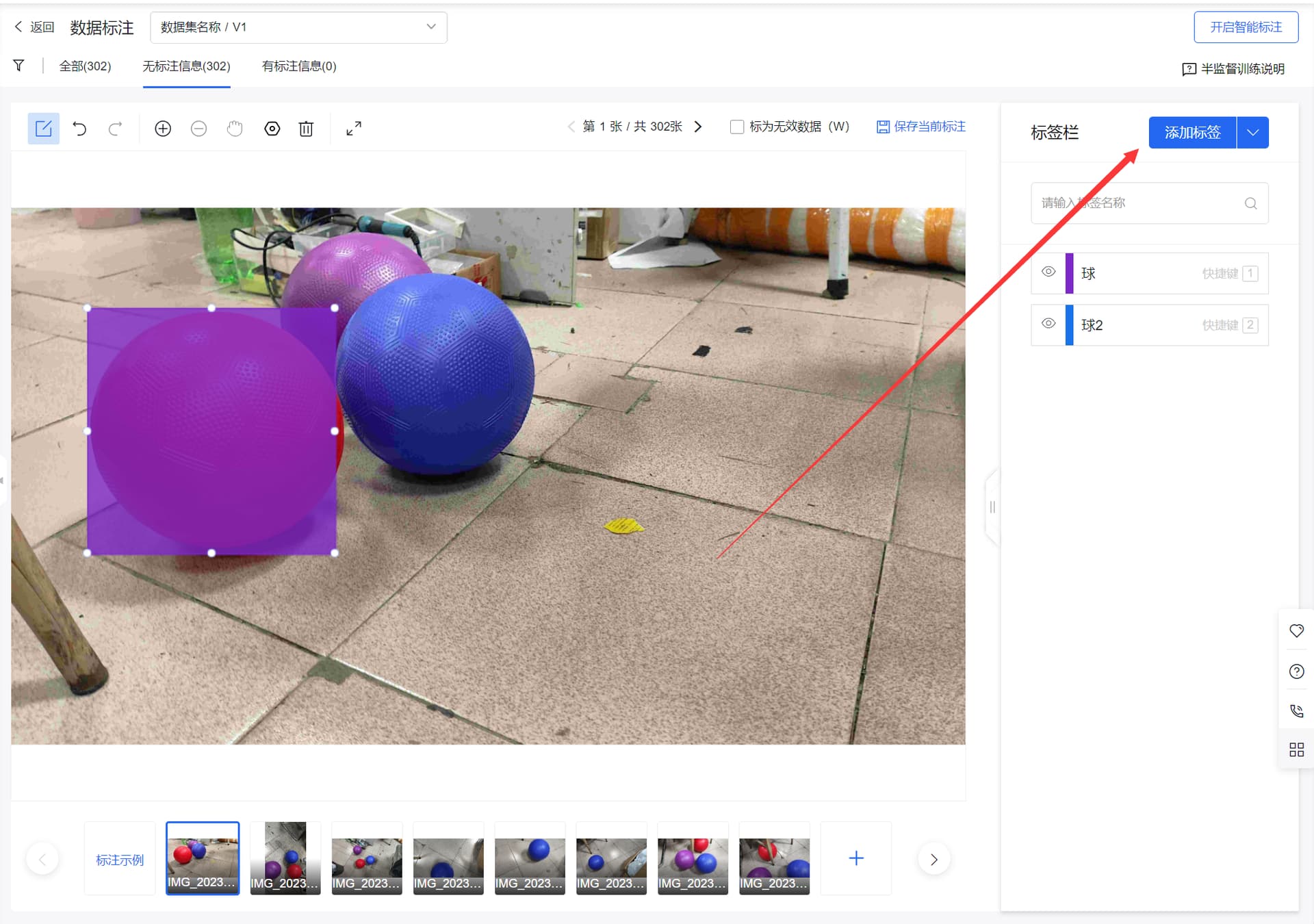
当标注了一定量的数据集之后可以开启智能标注
1.2.4 数据集增强(可选)
注意数据增强会显著提升数据集数量,一般配合数据清洗一起使用
1.2.5 导出数据集
导出需要在完整控制台:https://console.bce.baidu.com/easydata
导出格式选择xml(这会影响到后面的数据集格式转换)
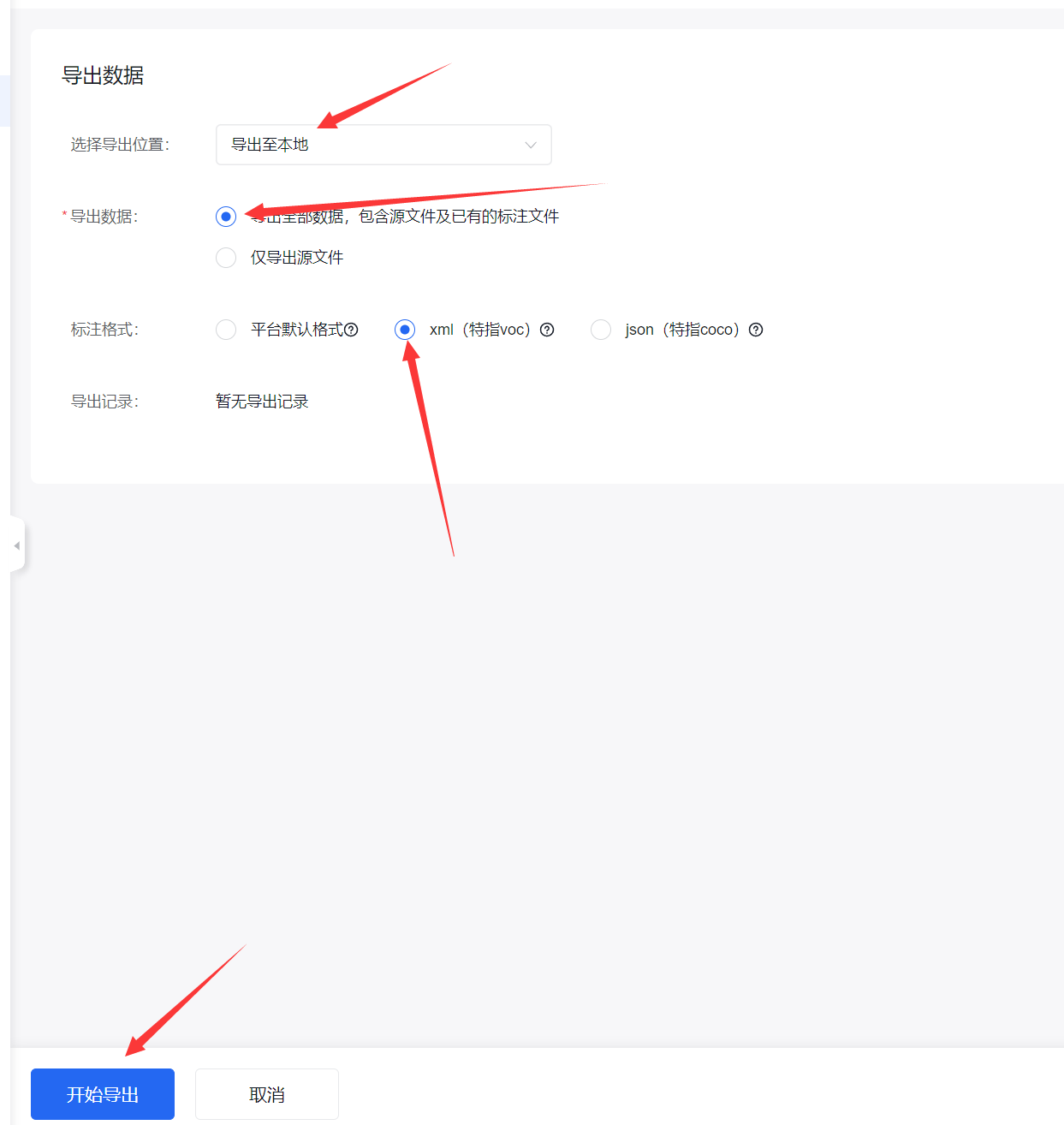
等待导出完成,即可在导出记录中下载数据集
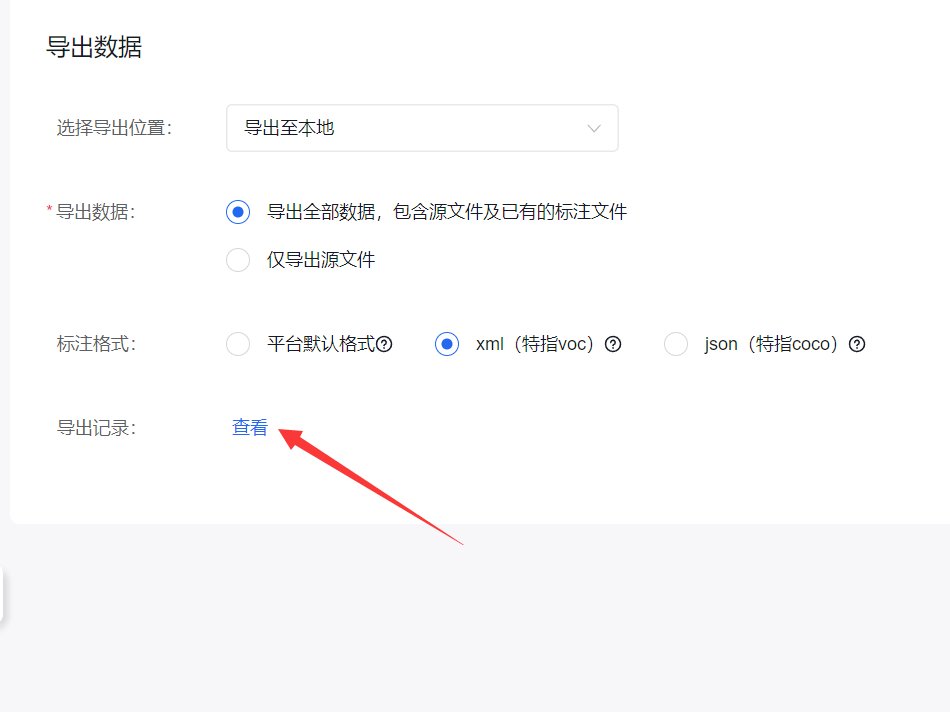
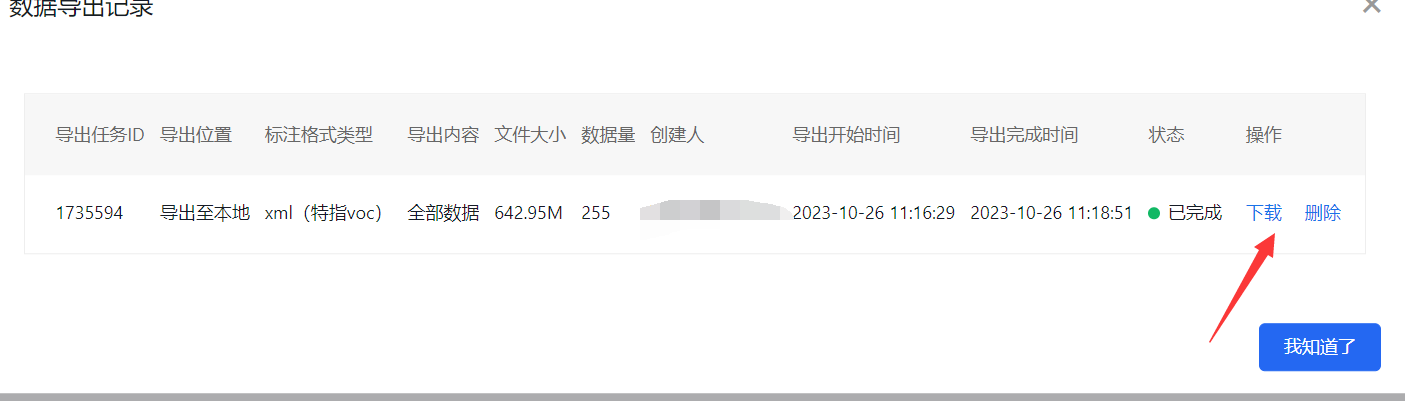
下载完成后解压即可得到数据集:Annotations是标签,Images是图片

1.3 数据集格式转换
1.3.1 yolo标注格式
由于yolo模型训练需要的标注文件是txt格式的,并且内容类似这样
2 0.04791 0.83935 0.09583 0.13611
1 0.31302 0.79166 0.075 0.13333
每一行代表了一个标注框,第一个数字为目标ID,后面的数字为标注框的xywh坐标
xywh坐标:x,y为标注框的中心坐标,w,h分别为宽度和高度,单位是占画面整体的比例,范围:0-1

1.3.2 转换标注文件
我们需要把xml文件转为txt文件,可以自己编写一个脚本
当然我们已经写好了,见此文档开头脚本-xml_to_txt.py
将xml_to_txt.py放在和Annotations文件夹同一目录下(注意不是Annotations下)
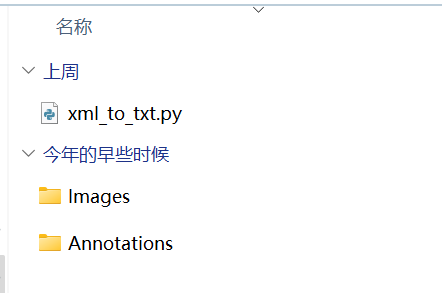
可以直接运行脚本,也可修改脚本将id与名称对应
运行脚本后得到labels文件夹,里面存放着txt格式的标注文件

1.3.3 数据集分组
训练时数据需要分成训练集,验证集和测试集,有时候会将验证集和测试集合并
其中训练集比例一般不小于50% 推荐70%
文件目录如下:
dataset #数据集
├── train #训练集目录
│ ├── images # 存放训练集图像文件
│ │ ├── train_image1.jpg
│ │ ├── train_image2.png
│ │ └── ...
│ └── labels # 存放训练集标注文件,以.txt格式
│ ├── train_image1.txt
│ ├── train_image2.txt
│ └── ...
├── val #验证集目录
│ ├── images # 存放验证集图像文件
│ │ ├── val_image1.jpg
│ │ ├── val_image2.png
│ │ └── ...
│ └── labels # 存放验证集标注文件,以.txt格式
│ ├── val_image1.txt
│ ├── val_image2.txt
│ └── ...
└── test #测试集目录
├── images # 存放测试集图像文件
│ ├── test_image1.jpg
│ ├── test_image2.png
│ └── ...
└── labels # 存放测试集标注文件,以.txt格式
├── test_image1.txt
├── test_image2.txt
└── ...
此时我们就需要将labels 和Images中的文件变成如上的结构。
你可以手动创建文件夹然后一个个复制粘贴,当然这很麻烦。
也可以写一个脚本来实现上面的功能,你们亲爱的学长当然也写好了,将split.py下载到和xml_to_txt.py相同的目录。
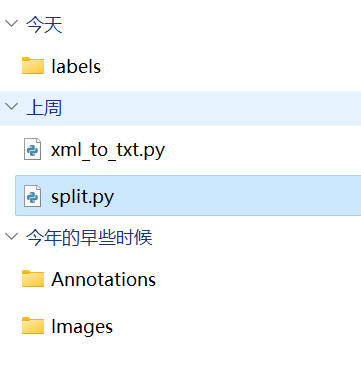
注意如果图片是PNG格式的运行split.py会报错,可以先运行png_to_jpg.py,如果图片全是png格式也可将split.py里面的.jpg换成.png
修改split.py里面的比例后运行,就可以得到训练用的文件夹

2. 训练
选择2.1或者2.2其中一种方式训练即可
2.0 准备yaml文件
创建一个yaml文件,比如data.yaml,内容如下
path: /home/featurize/data/ # 数据路径
train: #训练集路径
- ./train
val: #验证集路径
- ./val
test: #测试集路径
- ./test
# 数据格式
names:
0: 蓝球
1: 紫球
2: 红球
path: 这一项非常重要,如果不正确,训练时会报错。
当验证集和测试集相同时,路径val:和test: 也相同
其中names:下面0,1,2…对应标签txt文件中每行第一个数字,为类别id,未标注的类别将不会训练
需要将此数据集中的所有类别id与名称对应,右边的名称可以自定义
2.1 使用云GPU训练(推荐)
这里我使用 Featurize
2.1.1 上传数据集到Featurize
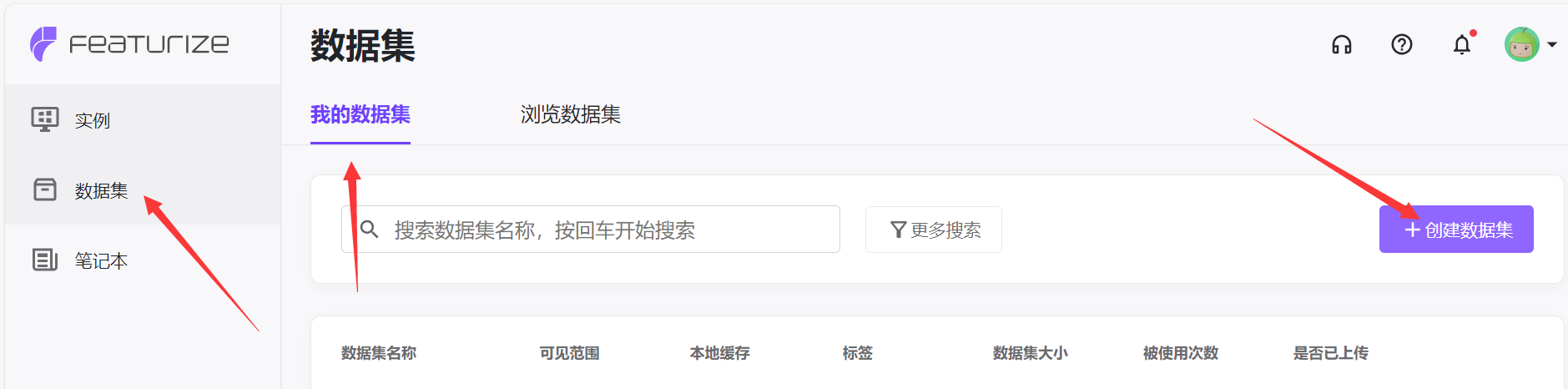
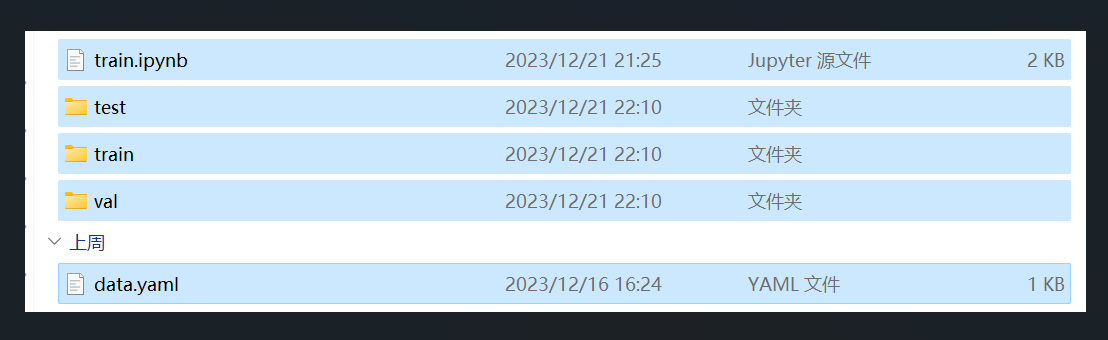
将这几个文件打包为zip,
train.ipynb为Jupyter笔记本文件,保存有几段代码,**等会训练时要用到,**文件也在文章开头
上传之后记得把权限改为仅自己可见,否则在一些比赛中可能会泄密
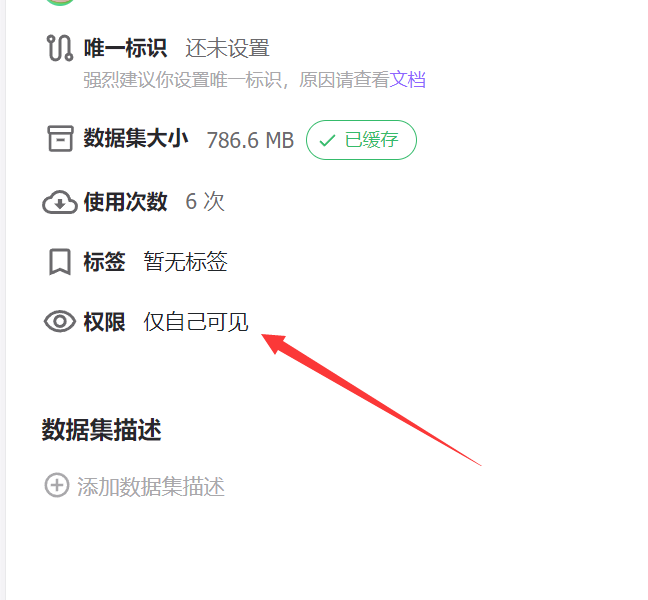
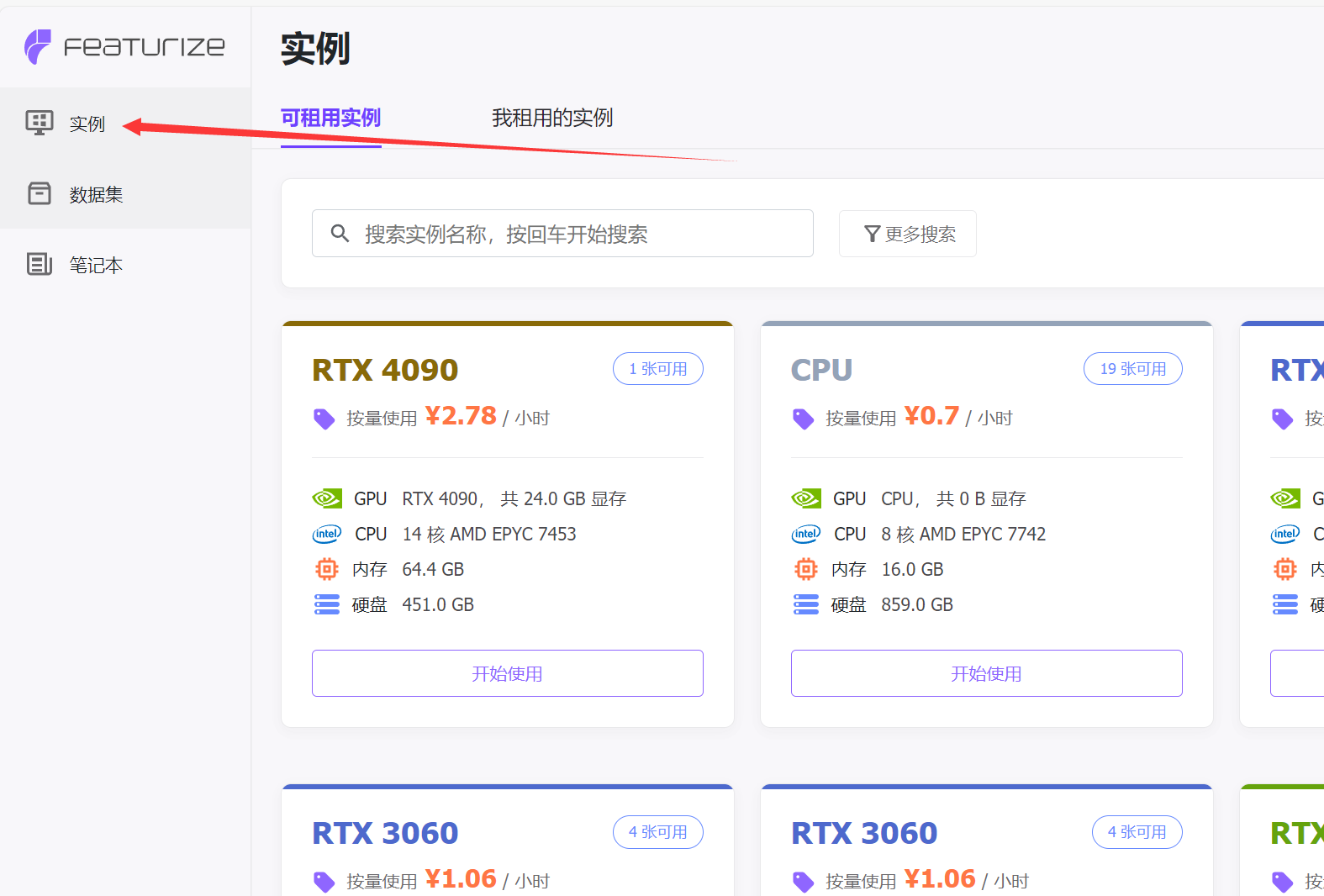
2.1.2 准备GPU实例
充好网费后点击一个GPU实例开始,显卡按需选择,一般推荐3060
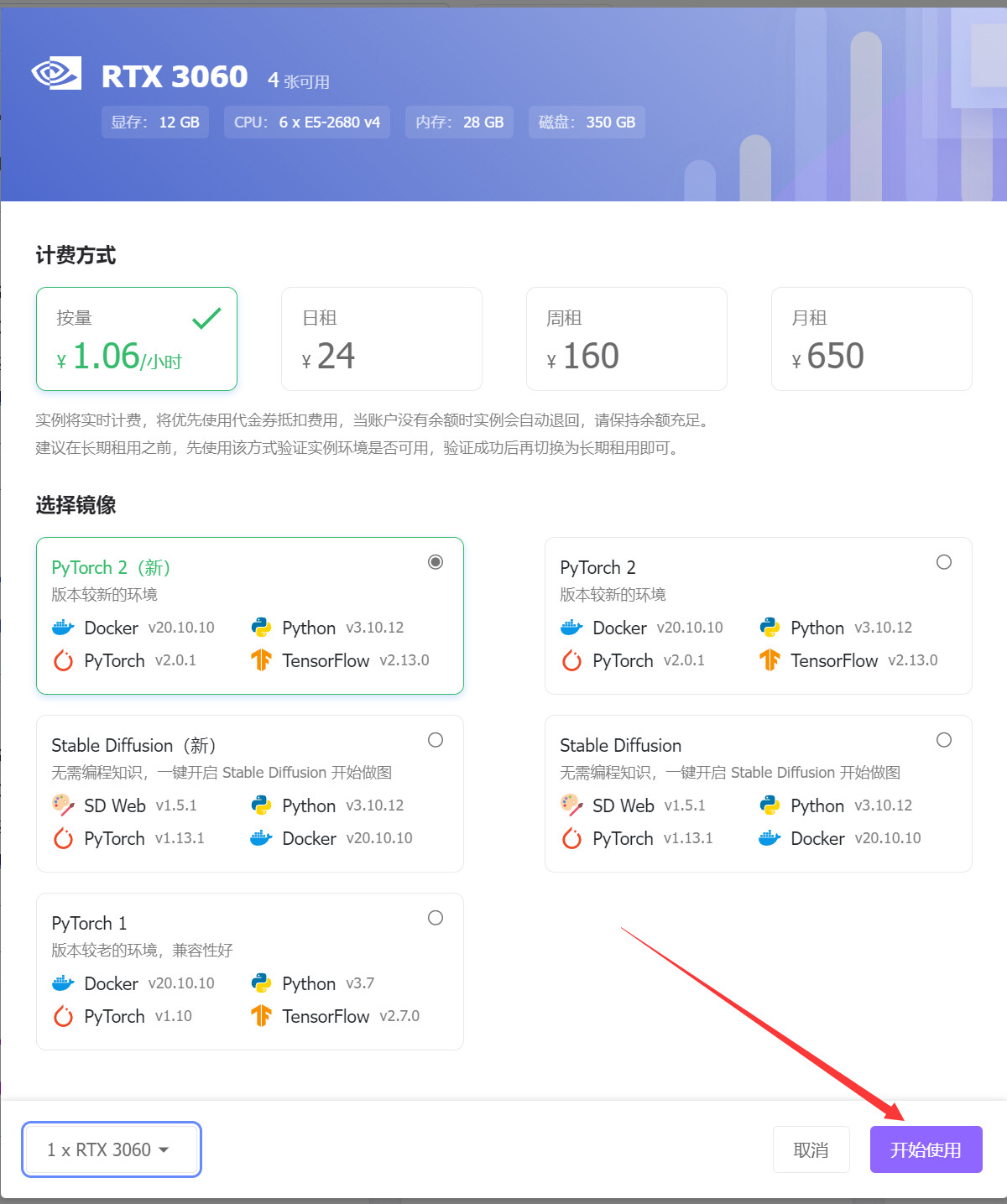
进入实例后点击添加数据集

添加好数据集之后数据会自动解压,可在左侧看见
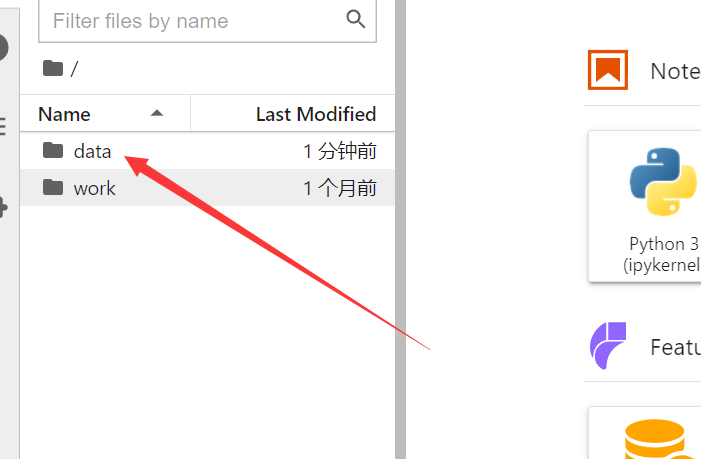
进入数据集文件夹,打开在2.1.1中准备的Jupyter笔记本文件
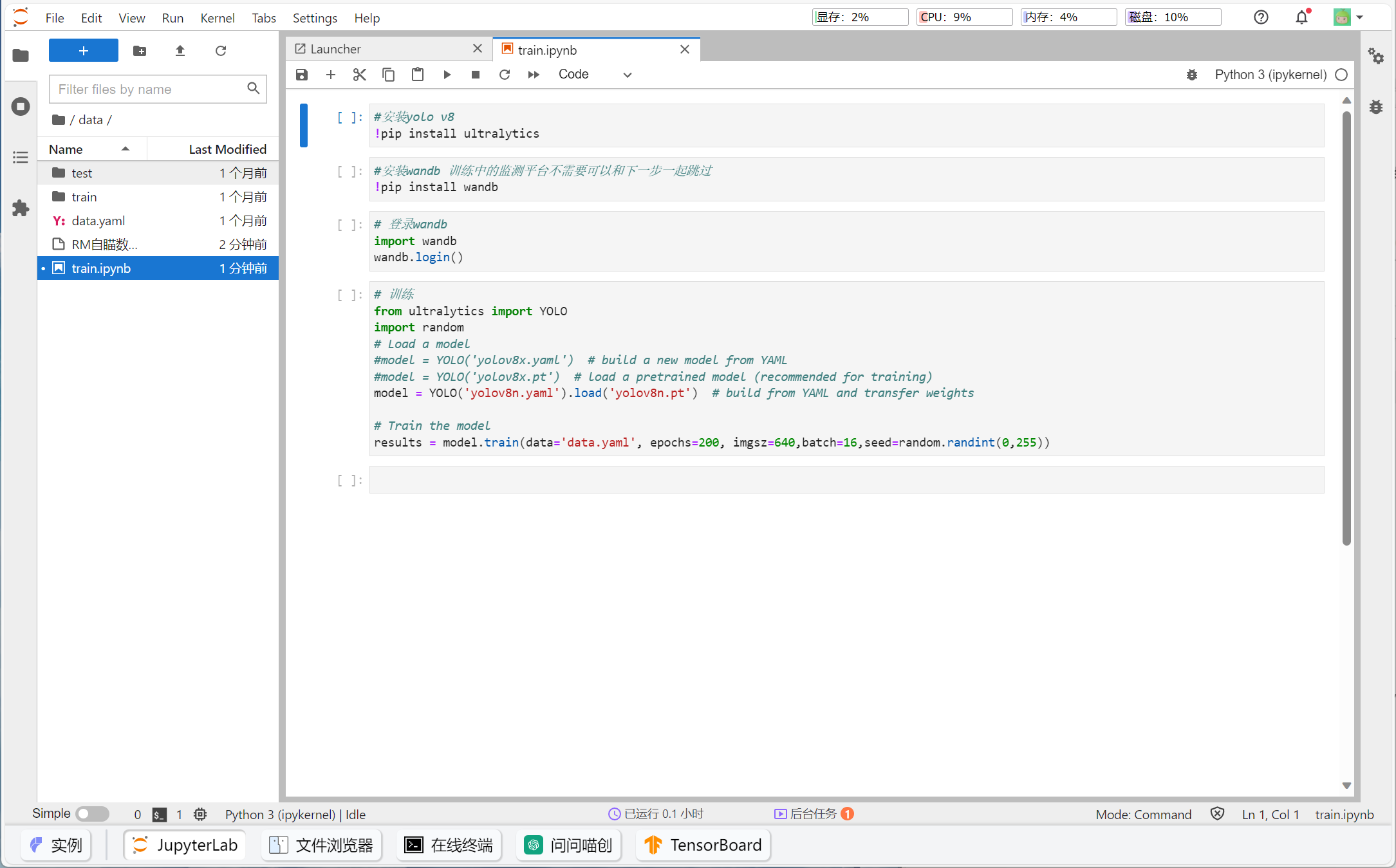
至此所有准备工作均已完成
2.1.3 开始训练
我们训练在Jupyter中完成
选中代码块,点击上方的箭头运行,或者Alt+Enter运行
yolov8目标检测模型一共有5个版本
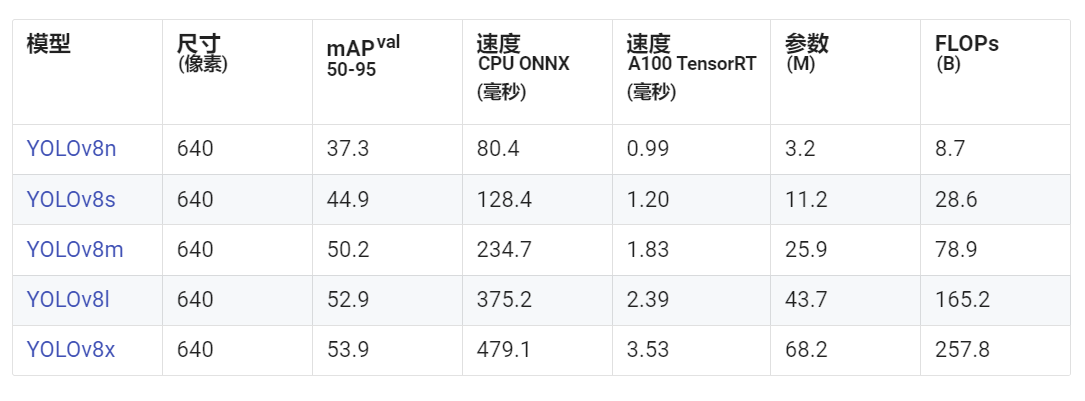
YOLOv8 Nano (YOLOv8n)是最快和最小的,而YOLOv8 Extra Large(YOLOv8x)是最精确但最慢的
参数越大性能开销越大,一般来说yolov8n就足够了
运行最下面的代码块即可开始训练
# 训练
from ultralytics import YOLO
import random
# 从下面三种方式中选一种加载模型
#model = YOLO('yolov8x.yaml') # 从yaml文件创建模型(随机初始化权重)
#model = YOLO('yolov8x.pt') # 从已经训练过的权重中载入模型
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从导入官方的权重(训练过的)
# 开始训练
results = model.train(data='data.yaml', epochs=200, imgsz=640,batch=16,seed=random.randint(0,255))
model.train()完整的参数列表在Train - Ultralytics YOLOv8 Docs中查看
这里我们只关注关键的几个:
data : 数据文件,为本文档2.0中准备的yaml文件
epochs: 训练轮数,推荐200-300,太低了会导致模型训练不充分,太高了浪费资源
imgsz: 模型输入图像的大小,大了会导致识别时长增加,小了会影响识别率,按需设定(非常重要)
batch: 每个批次的图像数(-1为自动调整),此项影响显存占用
seed:随机数种子,0-255
看到训练进度条即开始训练了
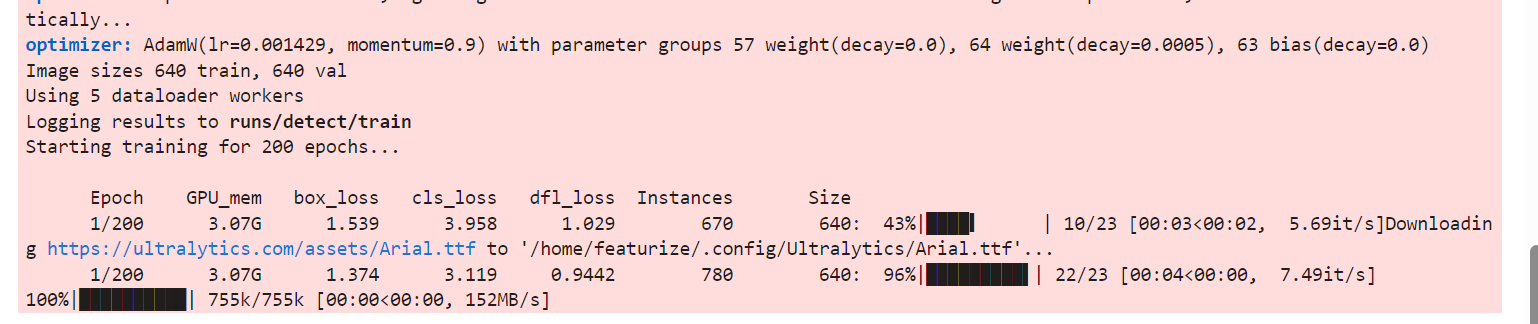
如果有报错请查看:2.4 常见报错&问题
2.2 本地训练
确保已经准备好pytorch + ultralytics 环境,选择2.2.1或者2.2.2其中一种方式即可
2.2.1 使用命令行训练
使用linux命令行或者windows cmd
控制台进入数据集目录后运行:
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=300 imgsz=640
完整的参数在:
Train - Ultralytics YOLOv8 Docs
这里我们只关注关键的几个:
data : 数据文件,为本文档2.0中准备的yaml文件
epochs: 训练轮数,推荐200-300,太低了会导致模型训练不充分,太高了浪费资源
imgsz: 模型输入图像的大小,大了会导致识别时长增加,小了会影响识别率,按需设定(非常重要)
batch: 每个批次的图像数(-1为自动调整),此项影响显存占用
seed:随机数种子,0-255
运行后出现报错请查看2.4
2.2.2使用python训练
创建一个python文件
# 训练
from ultralytics import YOLO
import random
# 从下面三种方式中选一种加载模型
#model = YOLO('yolov8x.yaml') # 从yaml文件创建模型(随机初始化权重)
#model = YOLO('yolov8x.pt') # 从已经训练过的权重中载入模型
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从导入官方的权重(训练过的)
# 开始训练
results = model.train(data='data.yaml', epochs=200, imgsz=640,batch=16,seed=random.randint(0,255))
参数同上
运行之后即可开始训练,出现报错请查看2.4
2.3 训练中模型数据说明
在训练过程中控制台会输出类似这样的数据

其中这样为某一轮训练的数据,我们可以通过这几个数据来评估什么时候结束训练

如果使用了wandb可以点击这个链接可视化查看训练情况
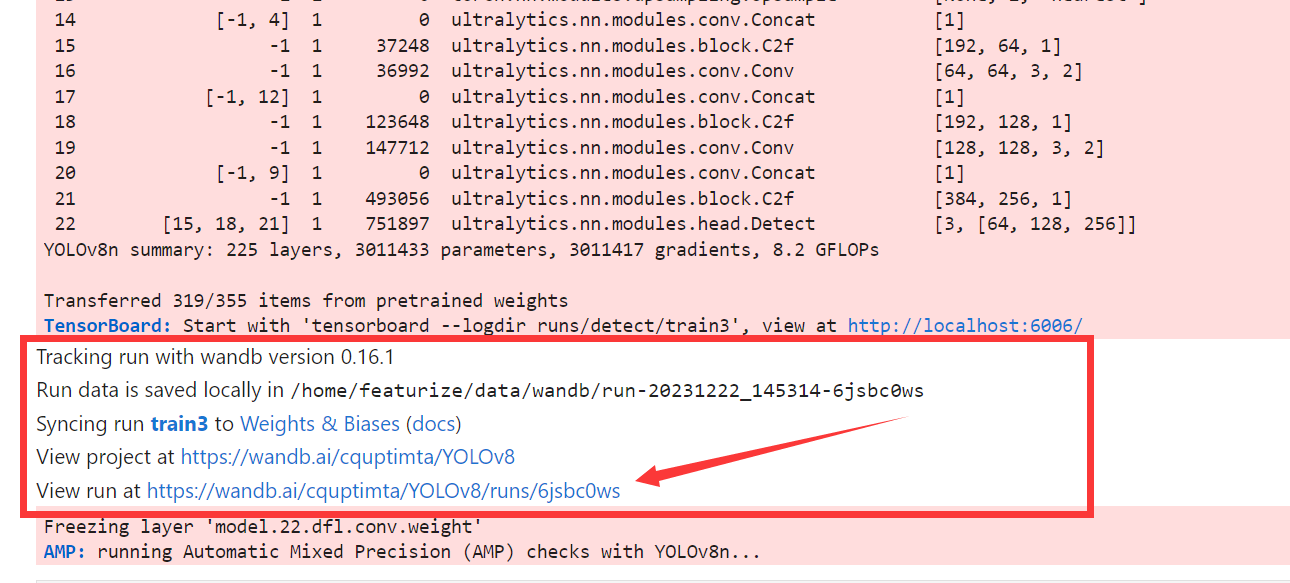
指标对应的意义请查看 0.4 一些概念的了解
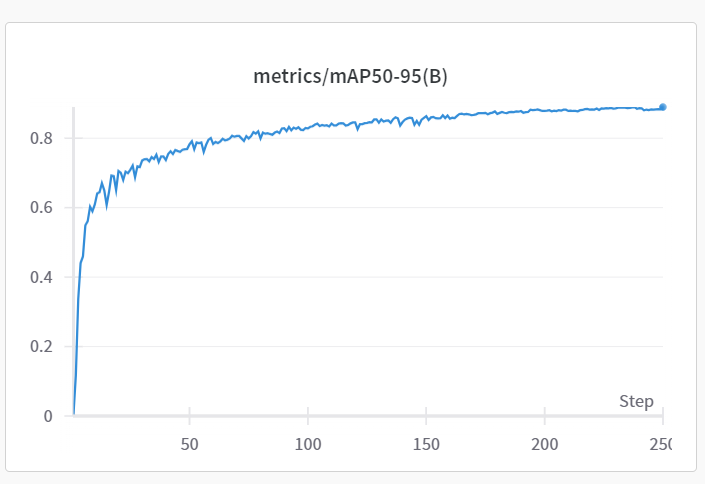
一般当各项值收敛一段时间后时结束训练
2.4 训练中的常见报错&问题
2.4.1 yaml文件中数据集路径错误

检查2.0中准备的yaml文件中的路径,在Featurize中解压后的文件路径为:/home/featurize/data/
2.4.2 显存不够
解决方法:
降低 imgsz
降低 batch
换显存更大的GPU
2.5 查看训练结果
训练结果会保存在当前目录下的runs/tarin{i}文件夹里面
![]()
注意,如果运行了训练命令多次,会产生多个train文件夹,注意分辨哪个是需要的
文件夹中有类似如下文件
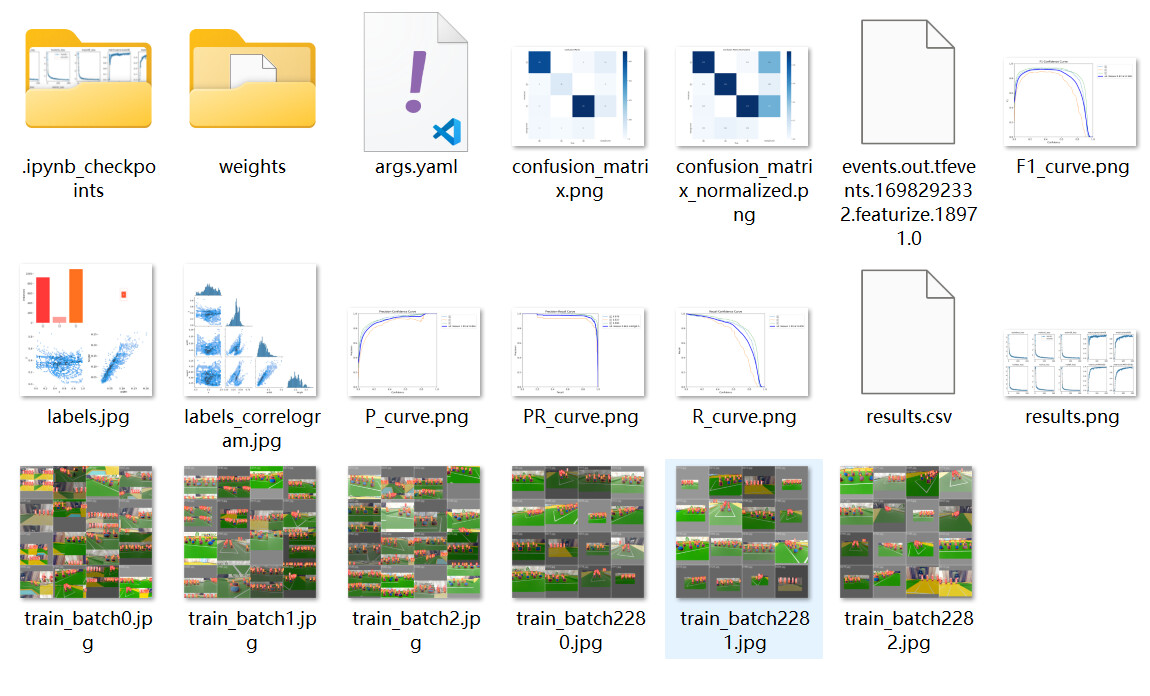
其中图片是一些参数的可视化
weights文件夹下是训练好的模型权重,best.pt是map最高的权重,last.pt是最后一次训练后的权重
weights #权重目录
├── best.pt
└── last.pt
如果是使用的云GPU记得下载train文件夹,防止训练结果丢失
3. 部署
官方文档地址,里面有示例和具体参数的说明。
https://docs.ultralytics.com/modes/predict
3.1使用python部署
需要提前准备好环境,否则会报错
将2.5中得到的权重文件放在脚本同目录下,一般使用best.pt
3.1.1 使用ultralytics库
python示例
from ultralytics import YOLO
#加载模型
model = YOLO('best.pt')
# 定义你的图像来源,可以是图片也可以是视频
source = './你的图片.jpg'
#获得结果,并显示
results = model(source,show=true)
运行这段代码即可查看模型效果。
注意运行上面的代码出现的物体的名称信息是由2.0中的yaml文件确定的,如果名称对应错误,请检查训练时的yaml文件
如果想获取方框位置等信息就要对results进行操作
results是个对象,具体属性请查看官方文档:
Predict - Ultralytics YOLOv8 Docs
3.1.2 使用opencv操作
一定要看一下官方文档:
Predict - Ultralytics YOLOv8 Docs
获取目标框的示例:
#.....省略了一部分代码
# 使用YOLOv8进行目标检测
results = model(frame)
# 获取检测框的xyxy坐标
boxes = results[0].boxes.xyxy.numpy()
# 获取检测框的置信度
boxes_conf = results[0].boxes.conf.numpy()
#.....省略了后面的处理
完整的示例:
#导入所需要的库
from ultralytics import YOLO
import cv2
import numpy as np
model = YOLO('best.pt')#载入模型
cap = cv2.VideoCapture(0) #这里使用摄像头作为图像源
while True:
ret, source = cap.read()
#source = resize(source,224,224) #有需要可以先对图像进行resize,resize函数需要自己写
results = model(source,verbose=False) #verbose参数控制控制台输出日志
#遍历得到的结果
for result in results:
# 获取包含边界框坐标的Boxes对象
# 检查空对象
if len(result.boxes) == 0:
continue
#获取Boxes对象
box = result.boxes
#遍历Boxes对象得到单独的box
#类别
object_class=box.cls.item()
#置信度
object_conf=box.conf.item()
#打印类别和置信度
print(object_class,object_conf)
#获取矩形框的坐标
point1,point2=(int(box.xyxy[0][0]),int(box.xyxy[0][1])),(int(box.xyxy[0][2]),int(box.xyxy[0][3]))
# 绘制矩形
cv2.rectangle(source,point1,point2,(0, 255, 0))
# 显示图像
cv2.imshow('Image', source)
# 退出功能
if cv2.waitKey(1) & 0xFF == ord('q'):
break
修订记录
v1.0
2023/12/21
CQUPT IMTA@QMJ
创建文件,爆肝内容
v1.1
2023/12/23
CQUPT IMTA@QMJ
完善训练部分的内容
v1.2
2024/8/8
CQUPT IMTA@QMJ
转换文档到mrdoc
v1.2.1
CQUPT IMTA@QMJ
转换文档图片到rcbbs.top