
以寒假KFS数据集制作为例,从图像采集——图像处理——标签制作——模型训练——效果检验几个方面介绍要点。
一.图像采集

寒假期间,我们的队员自主拍摄了大量的图像数据,共需制作32个字符的数据集,每个字符的图片训练量在500张上下(可根据最后训练情况自主调整数据量)。
图片采集的要点:
1.环境多样(最好是不同的环境,保证数据的多样)
2.图像基本清晰(由于后续图像处理可能影响图片像素)
3.若因环境受限,可采取数据增强获得大量图片(如将照片亮度调整,镜面、对称、反转等)
4.也可到网上寻找图片保存
5.拿到的图片最好按一定的命名格式重命名(方便整理,对后面图片汇总也可以防止名字重复带来一些不必要的麻烦)
二.图像处理
刚获得的大量数据可能由于操作失误可能存在中心物丢失,图片不清楚等问题,这时候需要剔除不良数据,保证数据集的“纯净”,另外,由于我们总图片多大10000张以上,为尽量减小内存占用(方便传输),需要对图片进行压缩处理(理想状态是15-30KB以内)压缩过渡同样会造成图像清晰度急剧丢失(部分模糊,出现马赛克),以及后续为了方便制作标签还要对图片进行重命名
压缩软件推荐(图压):免费,自主决定压缩倍率,适合批量压缩,应用商城即可下载
重命名图片python代码(后续标签同样由此)可由ai给出这里由于篇幅不给出
三.标签制作
首先推荐网站Makesense和Labeling(此处用Makesense)

标签基本要求:
1.首先导入所有标签名(此次有32个,则需将所有标签名放于同一txt文档内)
2.要求用最小相切矩形覆盖目标图片

四.模型训练
具体教程可上csdn搜索有更详细教程,此处只提醒讲解要点
1.尽量用GPU训练(CPU速度较慢)
2.预训练权重文件说明(后缀名分别有yolov5n.pt、yolov5s.pt、yolov5s-seg.pt、yolov5x.pt,n精度最小速度最快,x精度最大速度最慢,一般用s性价比最高)
3.也可修改训练轮数和单次输入图片量(主要调参数)
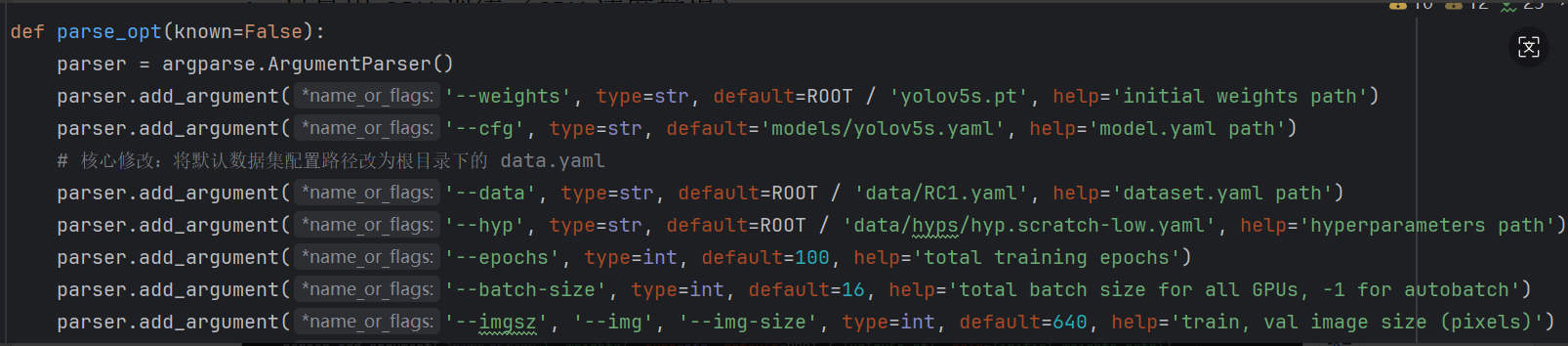
修改train.py的此处自定义函数epochs(一般100)即总训练轮数batch-size即批次大小(一般16,越大越慢,精度也越高),按实际情况修改
五.效果检验
训练完成后会得到两个权重文件
best.pt为最优权重(通常使用的就是best)在验证集上表现最好的模型权重
last.pt为最新权重训练最后一轮(epoch)保存的模型权重,last一般用于检验是否过拟合(模型在训练集上表现极好,但在测试集 / 新图片上表现很差。)
对比best和last权重的置信度,可以反映出数据问题
