
萝马干饭
上海交通大学交龙战队
关于工程视觉的一些小尝试
近日,萝马车圈特邀刚刚斩获RoboMaster“四冠王”荣誉的上海交通大学交龙战队 ,就工程视觉中的自动对矿 技术进行了思路分享,吸引了众多参赛队伍的广泛关注。
视频1.zip (1.4 MB)
场景重现
出处: 场地道具训练
视频2.zip (2.9 MB)
出处: 第二十八场 太原工业学院vs上海交通大学 第一局 蓝2工程
视频3.zip (1.8 MB)
自动对矿的思路
识别—识别兑换框的6D位姿
规划—规划机械臂末端移至识别位姿

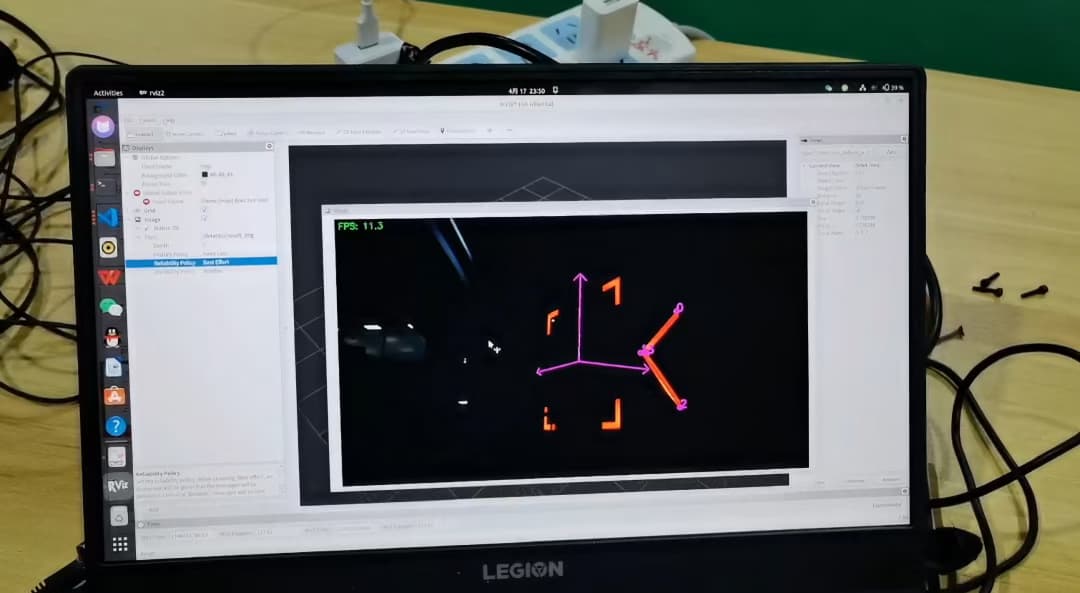
目标一:识别兑换框的6D位姿
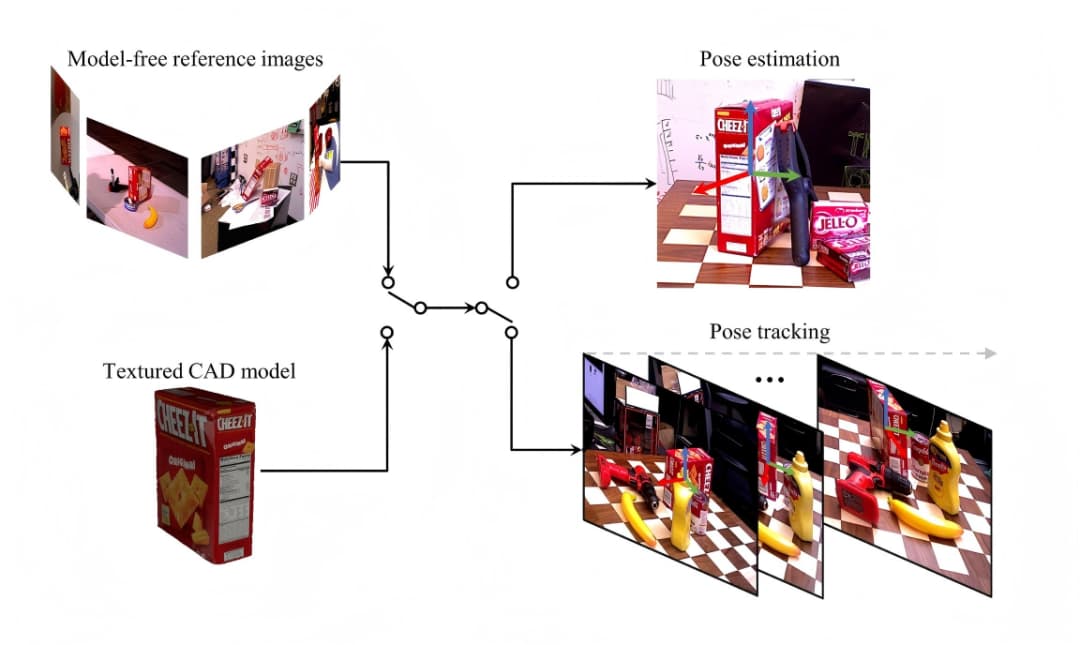
方案一:Foundation Pose
“We present FoundationPose, a unified foundation model for 6D object pose estimation and tracking, supporting both model-based and model-free setups. Our approach can be instantly applied at test-time to a novel object without fine-tuning, as long as its CAD model is given, or a small number of reference images are captured. ” — FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
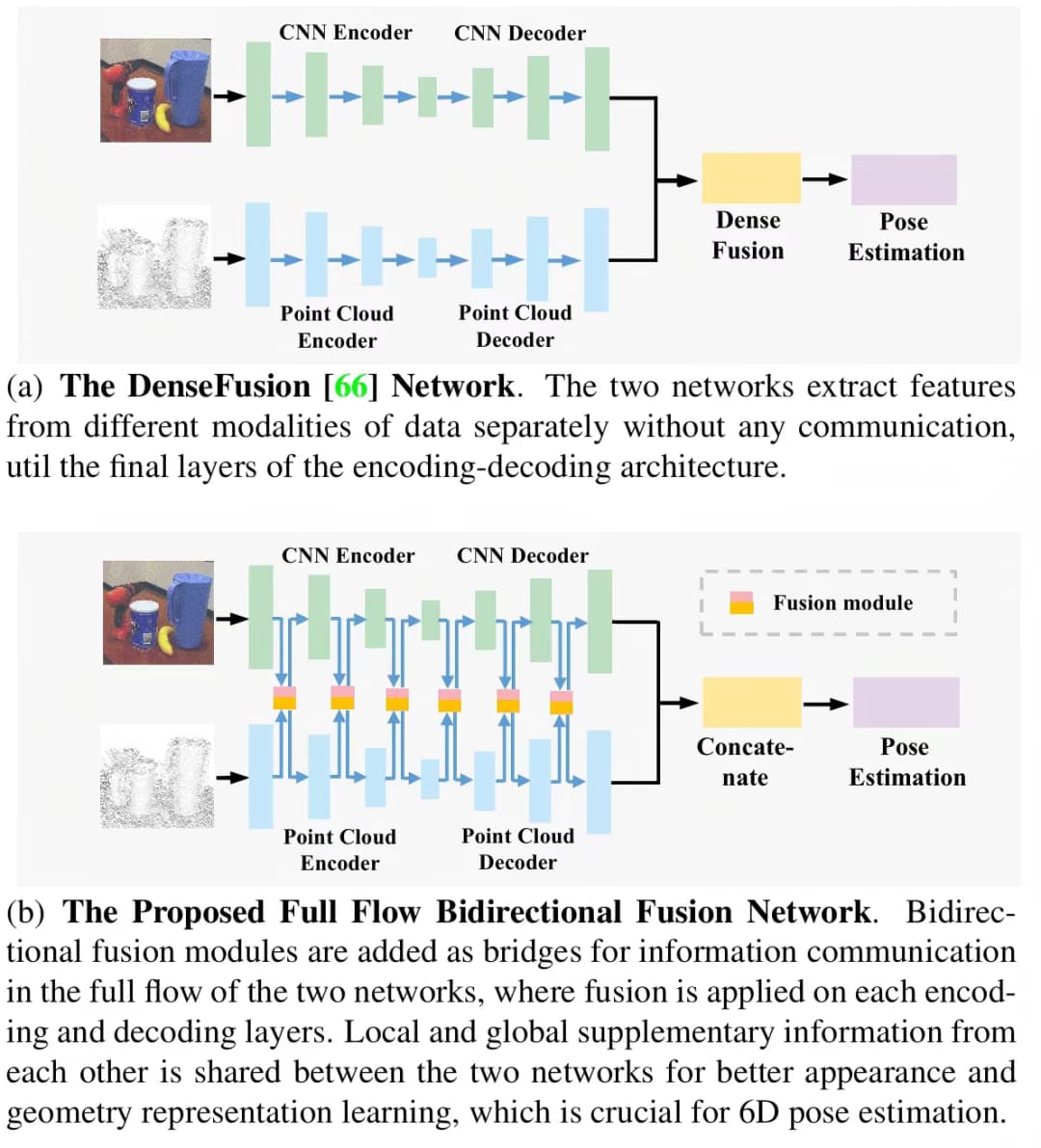
方案二:FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation
利用一张RGBD图片,使用端到端训练,为每个物体实例的姿态估计结果
方案三:视觉识别+PnP
利用兑换框的特征角点对正面或侧面进行视觉上的识别,得出兑换框在相机平面上的位姿;
再通过PnP还原出兑换框的真实位姿。
为什么选择视觉识别+PnP
— 识别的速度 —
车载小电脑的gpu算力有限
经测试,在4090上跑Foundation Pose或FFB6D方案的平均识别速度均超过1s
— 识别的精准度 —
Foundation Pose和FFB6D都是适用性极广的方案,虽然在大部分场景下均适用
但视觉兑矿的任务对识别的精度要求极高,需要识别误差在1cm以内
— Sim2real —
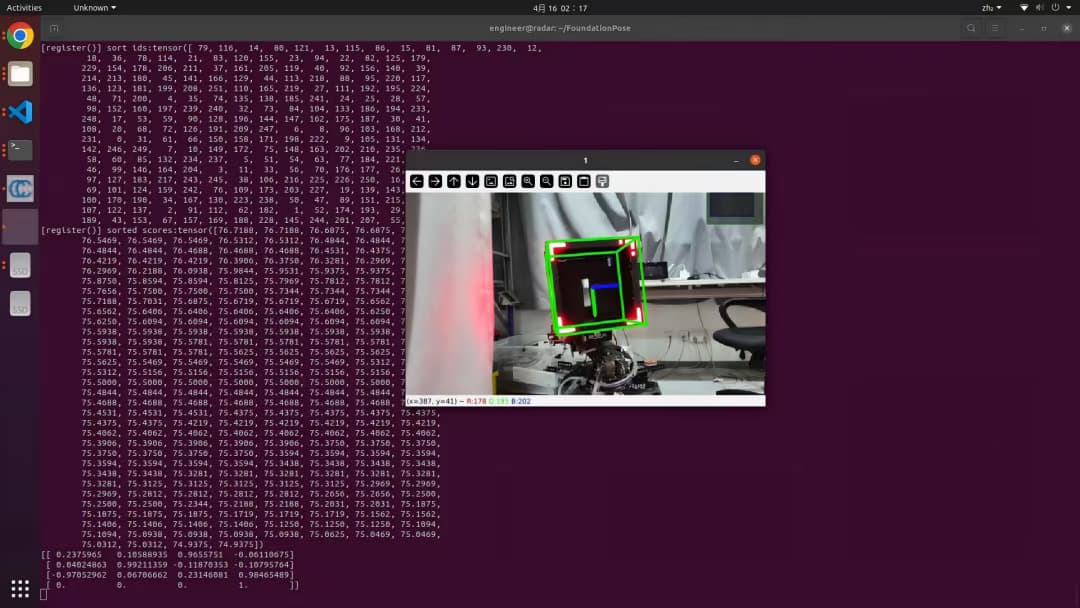
视觉识别
识别出标准特征角点(正面12个角点/侧面4个角点)在相机平面上投影出的位置,并使用PnP还原出这些特征角点在三维空间中的位置。
— 难点1:如何精准地识别出特征角点 —
- 传统OpenCV进行轮廓检测,并提取出转折点
-优点 :速度快,且普通情况下精准度高
-缺点 :鲁棒性很低,当图像有噪声或兑换框后的竖直灯条干扰时,识别准确度很低
- 神经网络训练模型识别
-优点 :速度较快,且识别鲁棒性高,基本能识别出角点的大致位置
-缺点 :识别精度低。由于侧面只有四个特征角点(即箭头的角点),在做PnP时每个点的微小误差会导致识别出兑换框位姿的rpy产生巨大变化
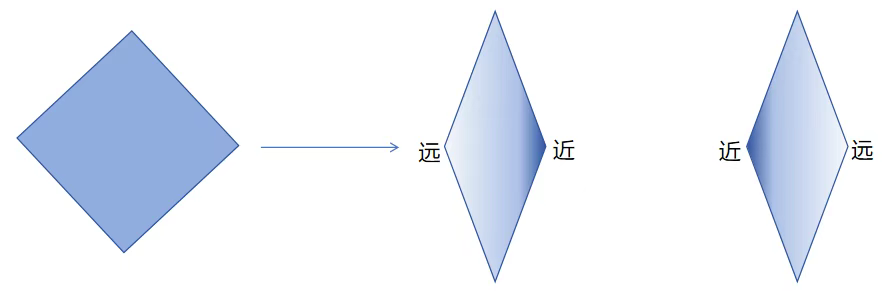
—难点二:关于PnP的两解问题—
- 原因 :在三维空间中,四个共面的点不能唯一确定一个刚体变换,它们位于一个二维子空间中,缺少对深度维度的约束,因此存在几何上的模糊。
—我们的方案—
- 使用神经网络模型预测+传统OpenCV识别
-先用神经网络模型预测出角点的大致位置,然后使用传统视觉算法进行进一步校准
-在图像二值化之后,使用OpenCV中的多边形拟合算法,将图案拟合成一个个的多边形;然后在所有的多边形角点中,找出距离预测大致位置最近的角点作为校准后的结果
-难点:调整cv::approxPolyDP的参数,使得在较远距离和较近距离均能获得较好的结果

- 使用深度信息甄选出正确的解
-同时利用深度相机录出的RGB信息和深度信息来识别:将同一时间拍出的RGB图片和深度图片对齐后,先求出识别的角点的位置,然后分别比较两种不同的PnP解对应的深度信息和深度图片中的深度信息是否吻合
-具体地,计算出兑换框角点roi区域的点云后,与深度相机拍出的点云进行逐点比较深度(pointwise comparison),偏差较小的那个解就是真实的位置信息
-缺点:非常依赖深度信息质量;当深度信息质量较差时,甄选解便容易选错,从而导致识别出兑换框位姿的yaw有很严重的偏差
—关于深度相机的选取—
- 双目深度相机(Intel Realsense、OAK等):
-兑换框表面缺乏纹理信息,立体匹配效果差
-黑色表面吸光,信噪比低
- ToF相机(Orbbec Femto Bolt):
-主动测距对无纹理表面效果好
-使用主动红外光和滤光片,抗干扰能力强


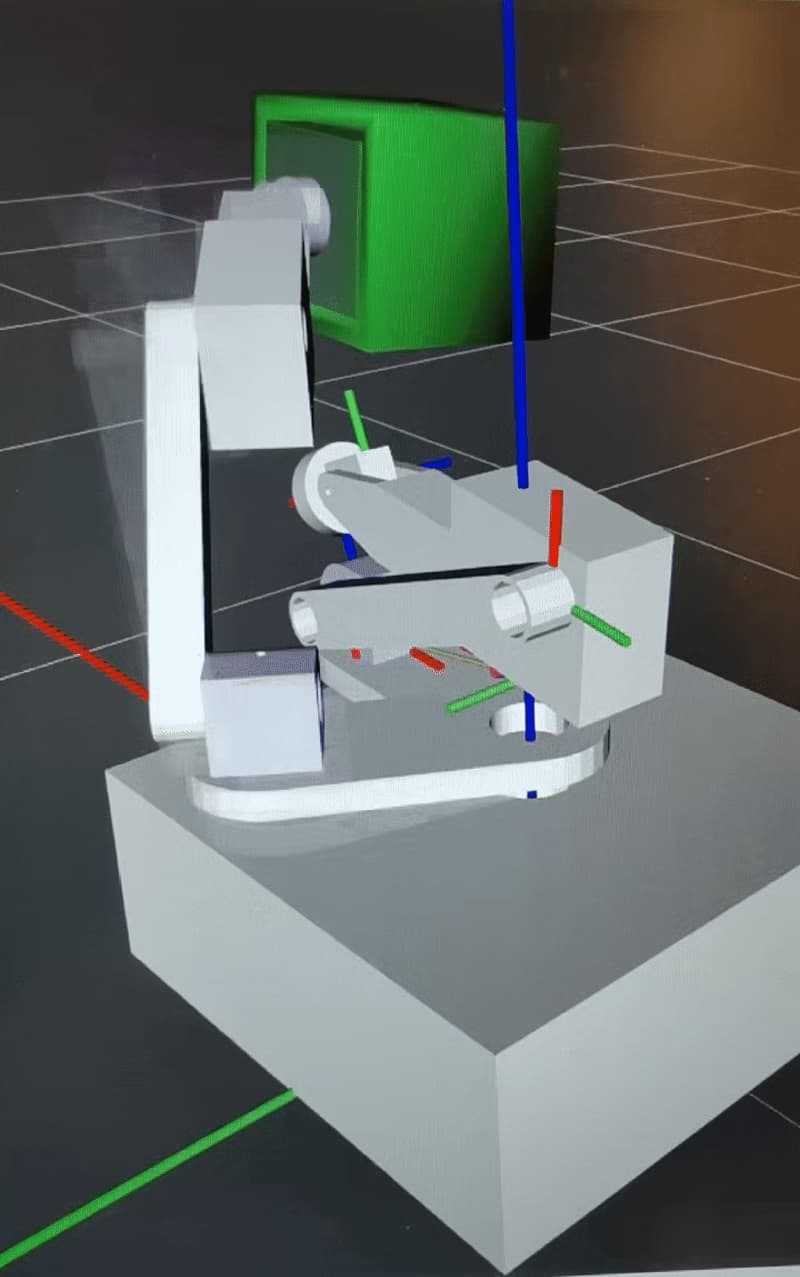
目标二:机械臂规划
难点
①在规划的过程中,机械臂或矿会撞到兑换框
②在规划的过程中,机械臂的工作空间受到限制,导致路径中的某些位置可能规划不到
我们的方案
采用moveit2作为运动规划框架,规划器选用ompl

— 难点一:规划失败 —
-
如果直接规划到最终推入位姿,在最后的推入阶段,由于末端轨迹的可行解少,基于采样的路径规划器难以快速找到解
-
将规划分成两步:先规划到预推入位姿,再规划矿石的推入路径
-
预推入位姿的选择:
-竖直推入 :将矿石先摆在兑换框开口处,沿着兑换框开口进行推入
问题:工作空间限制,在兑换框Pitch较大时(但官方四级矿好像不会出现?),预推入位姿会超出机械臂的工作空间
-旋转推入 :将矿石绕兑换框的某一棱/角进行旋转
优点:解决超出工作空间问题,对识别误差的容错率高

-
旋转推入轨迹选择:通过二分法求出绕不同中心旋转推入的最小残差角,选取残差角最小的
-
7DoF机械臂的多解问题:会导致预推入位姿与最终位姿的位形空间不联通
-
解决方案:正难则反,先通过逆解计算出最终的机械臂位姿,然后进行反向规划
难点二:规划速度慢
-
简化机械臂与兑换框及兑换站模型
-
多线程并行规划
-
更好的运算平台
-
调参
难点三:上下位机通信及控制
-
由于没有采用视控一体的控制方案,受制于通信延迟无法采用实时在线控制方案
-
离线控制 :上位机将规划出的轨迹中的各个关节角一并发给下位机,由下位机在各个点间进行插补
-设置相邻两轨迹点的时间间隔为50ms
-运动轨迹不符合预期?控制时添加速度前馈
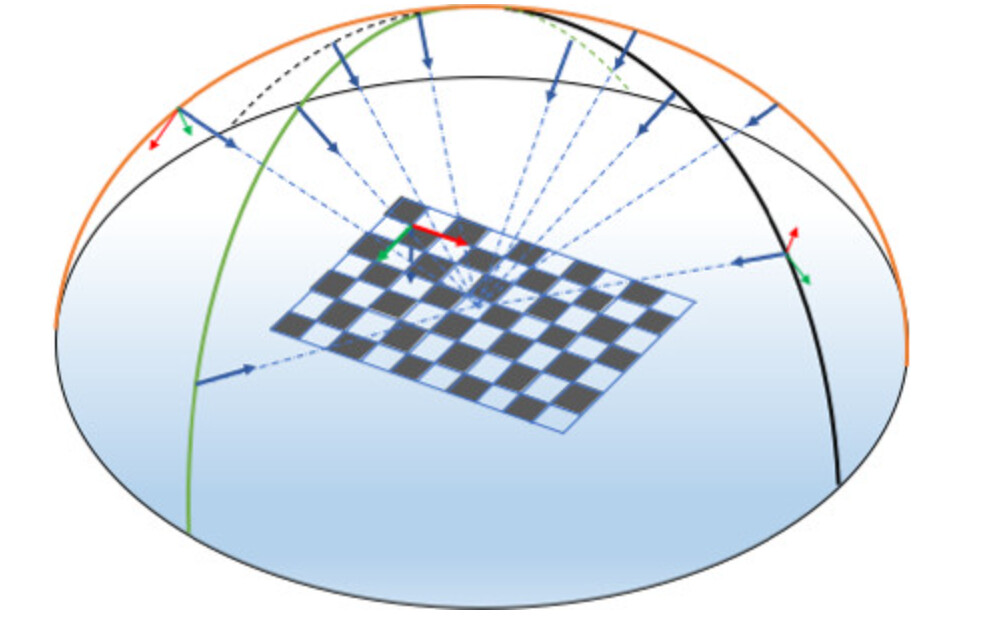
—相机外参标定—
-
标定相机坐标系到某一个关节的坐标系的位姿变换
-
通常方法:使用OpenCV标定板/Aruco Tag,并在保持世界坐标系恒定的条件下录入20~30组数据,最后使用visp库的handeye calibration
(参考https://visp-doc.inria.fr/doxygen/visp-daily/tutorial-calibration-extrinsic.html)
- 如果你发现标出来外参后,矿还是没有运动到视觉的规划点,可以试试手动调整
—关于误差分析—
- 可能误差来源于:
-视觉识别产生的预估位姿的误差 (次要)
-相机外参不准确导致的误差 (次要)
-气泵出矿产生的误差 (主要)
-机械臂及底盘的移动导致的误差 (次要)
- 目前我们的出矿采用的是矿仓存矿+tof检测距离的方式;为了允许工程机器人下两级台阶而不掉矿,我们在矿仓下添加了蚊香板进行减震,但这也增加了出矿的误差
—如何减小出矿的误差—
- 采取深度信息识别出矿位姿:在深度相机录制的点云数据中,根据距离及轮廓分割出吸盘上矿石的点云并进行拟合,然后计算出矿被吸在吸盘上的位置
To be continued…
- 自动兑矿流程设想——采用“看”三次的方式:
- 一“看”—看自己位置 :通过深度生成点云并使用点云配准算出自己相对于整个兑换站的位姿
-二“看”—看兑换框位姿 :保持底盘不动,在兑换框移动后进行识别,求出兑换框的大致位姿(由于距离较远而识别可能不是很精准),然后规划出底盘移动到的位置,并操控底盘移动。由于底盘的控制不是很精准,且远处的识别也有些偏差,我们还需要获取一次兑换框位姿
-三“看”—看兑换框位姿 :在底盘移动结束后再看一次,求出兑换框的精准位姿,然后规划出机械臂的移动路径
(由于时间及人力原因我们只在仿真中完成了上述方案,并没有上车测试)
- 半自动工程
写在最后:
在萝马车圈,我们相信知识的力量,技术的深度,以及分享的温度。本次分享的完整资料,近期会发布在萝马车圈B站,敬请期待。

如果想进行更多的互动和讨论,欢迎关注萝马车圈B站账号,也可关注微信公众号,后台留言您的需求,我们将第一时间为您送上所需资源。